2.6 向链表★3◎4
2.6 双向链表★3◎4 在单链表中,每个结点的指针域只记载了其直接后继结点的地址,查找时我们只能从当前结点
作者
2.6 双向链表★3◎4
在单链表中,每个结点的指针域只记载了其直接后继结点的地址,查找时我们只能从当前结点“向后”查找。如果需要查找某结点的前驱信息,就必须从头结点开始向后查找(即使是循环单链表也一样),这是单链表的一个缺陷。
为了弥补这个缺陷,我们通常在结点的指针域中增加一个指向其直接前驱结点地址的指针,有了这个指针,就可以“向前”遍历链表了,我们称这样的链表为“双向链表”。
1.双向链表的表示
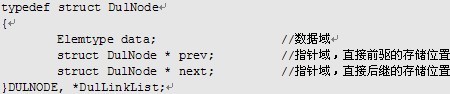
如下定义了一个数据元素类型为Elemtype的双向链表。
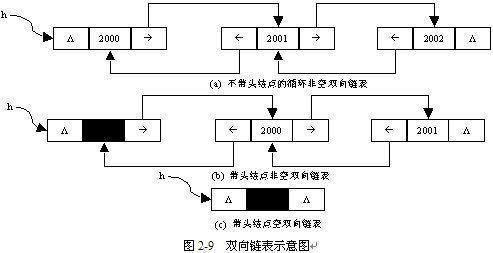
与单链表一样,双向链表也可以分为带头结点的双向链表和不带头结点的双向链表两种,如图2-9所示。
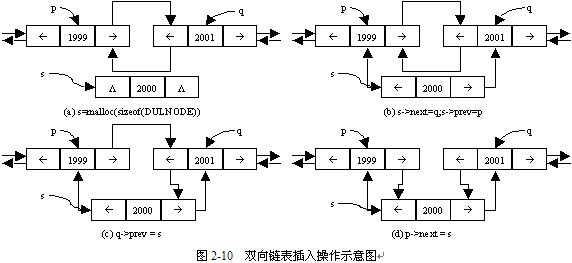
2.双向链表的插入算法
已知p为指向双向链表中某一个结点的指针,q为指针p所指向结点的后继结点的指针,即“q = p->next”,p不为空,当p指向链表中最后一个结点时,q取值为空。在该结点后插入新结点的过程分为4个步骤:
①分配新结点空间,定义s为指向该结点的指针,并赋值s所指向结点的数据域取值,如图 2-10(a)所示。
②定义s所指结点的后继结点为q所指向的结点,即“s->next = q”;定义s所指结点的前驱结点为p所指向的结点,即“s->prev = p”,如图2-10(b)所示。
③如果p所指向结点不是链表的最后一个结点,则q不为空,定义q所指向结点的直接前驱结点为s所指向的结点,即“q->prev = s”,如图2-10(c)所示。
④定义p所指向结点的直接后继结点为s所指向的结点,即“p->next = s”,如图2-10(d)所示。
由于在带头结点的双向链表中,p不可能为空,其插入算法如以下代码所示:

其中,当在双向链表尾插入时“p->next”取值为空,故无须执行第3步。
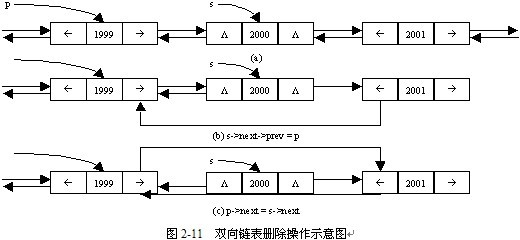
3.双向链表的删除算法
已知s为指向双向链表中某一个结点的指针(假设s不为空),删除该结点后的过程分为两步,其中p是指向待删除结点的前驱结点的指针。
(1)如果s所指向结点不是链表的最后一个结点,则s所指向结点存在后继结点,即“s->next”不为空,定义此后继结点的前驱结点为p所指向结点,即“s->next->prev = p”,如图2-11(b)所示。
(2)定义p所指向结点的后继结点为s所指向结点的后继结点,即“p->next = s->next”,当s所指向结点为链表最后一个结点时,等价于“p->next = NULL”,如图2-11(c)所示。
由于在带头结点的双向链表中,p不可能为空,其删除算法如以下代码所示:

其中,删除双向链表尾结点时“s->next”取值为空,故无须执行第1步。
4.双向链表的特点
与单链表相比较,双向链表具有如下特点:
(1)从任意一个结点开始,可以查找链表中的其他任意结点。
(2)既可以依照后继的方向(向后)遍历,也可以依照前驱的方向(向前)遍历。
(3)每个指针域中都增加了一个存储指针的空间,降低了存储密度。
双向链表通过增加一定的空间复杂度,降低了向前遍历的时间复杂度。
关于"最后阶段,真题的正确打开方式_备考经验_考研帮"有15名研友在考研帮APP发表了观点

扫我下载考研帮
最新资料下载
- 2024-03-15考研资料免费分享,公共课专业课都有,23最新的
- 2024-03-1125考研公共课免费分享
- 2024-03-06mpa复试
- 2024-03-0624新传考研资料 适用多种院校
- 2024-03-0624、25考研公共课免费分享
- 2024-03-05831程序设计语言
- 2024-03-05求资料
2021考研热门话题进入论坛
- 2022-01-24【入版必看】2021考研全程备考规划!
- 2021-12-16424分上岸!21级成都大学广播电视第1名三跨二战上岸经
- 2021-01-20学长学姐帮2020还没对你说的话,今天这就告诉你
- 2024-02-21西南交通大学土木考研
- 2024-01-31华中师范语言所考研资料
- 2024-01-31华中师范大学语言所考研资料
- 2024-01-27武汉大学法学学硕考研经验贴
考研帮地方站更多
你可能会关心:
来考研帮提升效率




